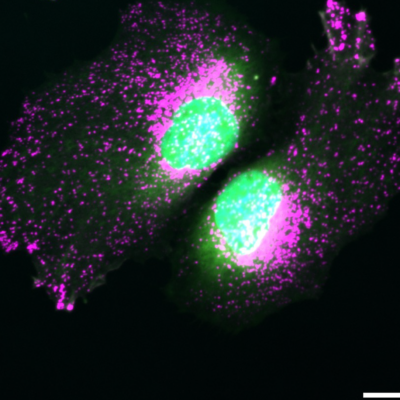
Wenn sich neue Viren oder Bakterien auf Menschen ausbreiten, muss rasch geklärt werden, welche besonderen Merkmale sie haben. Warum ist zum Beispiel das Coronavirus gegen übliche Medikamente resistent? Neue Big-Data-Technologie kann künftig dazu beitragen, die Besonderheiten neuer Viren- und Bakterienstämme in kurzer Zeit zu ermitteln. Dafür vergleicht sie das Erbgut eines einzelnen Organismus mit dem Genom-Bestand aller Stämme einer Spezies. Dieses Verfahren kann auch für höher entwickelte Lebewesen wie Säugetiere genutzt werden. Das neue Projekt „Pangaia“ an der Universität Bielefeld erforscht, wie sich die dabei verwendeten Datenmassen so ordnen und analysieren lassen, dass sie für die Biomedizin nutzbar sind.
Die Universität ist eine von elf Projektpartner*innen aus Europa und Nordamerika. Die EU fördert das Projekt über drei Jahre mit 1,14 Millionen Euro.
Wenn Biomediziner*innen klären wollen, ob das Erbgut eines Lebewesens besondere Abweichungen aufweist, nutzen sie üblicherweise ein Referenzgenom. Dafür werden mehrere Genome so kombiniert, dass sie die typischen Eigenschaften einer ganzen Spezies aufweisen. So können Forschende ein neues Grippevirus mit einem Referenzgenom vergleichen, das typische Merkmale der Vorgänger-Virenstämme zusammenfasst.

„In diesen Fällen vergleichen wir nur zwei Genome miteinander – Unterschiede und Gemeinsamkeiten sind am Computer relativ leicht zu erkennen“, sagt Professor Dr. Jens Stoye von der Technischen Fakultät, der mit seiner Arbeitsgruppe Genominformatik an Pangaia beteiligt ist. „Der neue Ansatz kann die Zahl der Vergleichsgenome bis zum Tausendfachen vergrößern.“ Diese Erforschung des Gen- Repertoires einer Population nennen die Forschenden „Pangenomik“.
Technologie eignet sich auch, um Erbkrankheiten zu erkennen
„Das Problem an der computergestützten Pangenomik war bisher die Unübersichtlichkeit durch die Masse an Daten“, sagt Professor Dr. Alexander Schönhuth von der Technischen Fakultät, der seit Januar 2020 die Arbeitsgruppe Genom-Datenwissenschaft leitet. Er koordiniert das Bielefelder Teilprojekt von Pangaia. Wie Jens Stoye forscht er mit seiner Gruppe am Centrum für Biotechnologie (CeBiTec) der Universität Bielefeld.
Genetische Daten werden mit den Buchstaben A, C, G und T dargestellt. Sie stehen für die Nukleotide, die Bausteine des Erbguts. Genome bestehen mitunter aus Milliarden dieser Informationseinheiten. Um sie besser zu vergleichen, können sie als „Buchstaben-Ketten“ nebeneinander angezeigt werden. Diese traditionelle sequenzbasierte Darstellung ist heute verbreitet. „Doch bei Hunderten von Vergleichsgenomen kostet es sehr viel Zeit, schrittweise zu analysieren, wie sich das zu untersuchende Genom von jedem der Vergleichsgenome unterscheidet“, sagt Schönhuth.
„Die neue Technologie ermöglicht die gleichzeitige, integrierte Analyse vieler Stämme desselben Organismus. Das können Viren, Bakterien und mitunter auch höhere Lebewesen sein“, erklärt Jens Stoye. „Damit lassen sich Gemeinsamkeiten und Unterschiede der einzelnen Mitglieder hervorheben. Bei Krankheitserregern lassen sich häufig sogar die Abläufe, die bei zur Entstehung besonders infektiöser Stämme geführt haben, verstehen und vorhersagen.“ Die Technologie kommt auch in Frage, um bei Menschen Erbkrankheiten zu erkennen oder um zu ermitteln, welche Mutationen in einem Tumor zum starken, krankhaften Wachstum geführt haben.
Forschende entwickeln neue Algorithmen und Datenstrukturen
„Um die computergestützte Pangenomik schneller und anwendungsfreundlicher zu machen, wollen wir mit unseren Projektpartner*innen in den nächsten Jahren neue Algorithmen und Datenstrukturen entwickeln“, sagt Schönhuth. Ein Ziel sind Algorithmen für Variationsgraphen. Mit diesen Handlungsvorgaben suchen die Computer nach Gemeinsamkeiten und Unterschieden zwischen den Vergleichsgenomen und stellen das Ergebnis grafisch dar: „Variationsgraphen erlauben die schnelle und hochaufgelöste Unterscheidung von krankheitserregenden und ungefährlichen Varianten eines Virus“, sagt Schönhuth. „Insbesondere erlauben sie auch die Identifikation von ganz neuartigen Mutationen, wie sie vermutlich bei der aktuell in China ausgebrochenen Variante des Coronavirus aufgetreten sind und zu Resistenzen gegen die üblichen Medikationen geführt haben.“
Das Projekt Pangaia heißt mit vollem Namen „Pan-genome Graph Algorithms and Data Integration“ (Graph-Algorithmen und Datenintegration für Pangenomik). Es läuft vom Januar 2020 bis Dezember 2023. Die Europäische Union fördert Pangaia über ihr Forschungsrahmenprogramm Horizont 2020. Die Universität Mailand (Italien) koordiniert das Projekt. Weitere Partner*innen außer der Universität Bielefeld sind: die niederländische Wissenschaftsorganisation NWO, die Comenius-Universität Bratislava (Slowakei), die Biotech-Unternehmen Geneton (Slowakei) und Illumina Cambridge (Großbritannien), das Institut Pasteur (Frankreich), die Simon Fraser University (Kanada), die Universität Tokio (Japan), die Cornell University und die Pennsylvania State University (beide USA).
When new viruses or bacteria spread to humans, it is essential to clarify their special characteristics as quickly as possible. For example, why is the coronavirus resistant to common drugs? In the future, new Big Data technology can help to identify the characteristics of new strains of viruses and bacteria in a short time. It does this by comparing the genome of a single organism with the genome of all the strains of a species. This procedure can also be used for more highly developed organisms such as mammals. The new project ‘Pangaia’ at Bielefeld University is investigating how the masses of data used in this process can be ordered and analysed for use in biomedicine. The university is one of eleven project partners from Europe and North America. The EU is funding the project with 1.14 million euros over three years.
When biomedical scientists want to find out whether the genetic material of a living being shows particular variations, they usually use a reference genome. They combine several genomes in such a way that they exhibit the typical characteristics of an entire species. This enables researchers to compare a new influenza virus with a reference genome that summarizes the typical features of the virus strains from which it originates.

‘In these cases, we compare only two genomes with each other—differences and similarities are relatively easy to identify on the computer,’ says Professor Dr Jens Stoye from the Faculty of Technology, who is taking part in Pangaia with his Genome Informatics research group. ‘With the new approach, we can compare one genome to thousands of other genomes in a single step.’ Researchers call this exploration of the genetic repertoire of a population ‘pangenomics’.
‘Until now, the problem with computer-assisted pangenomics has been the lack of transparency caused by the mass of data,’ said Professor Dr Alexander Schönhuth from the Faculty of Technology, who has been head of the Genome Data Science working group since January 2020. He is coordinating Bielefeld’s Pangaia sub-project. Like Jens Stoye, he and his group are carrying out research at Bielefeld University’s Center for Biotechnology (CeBiTec).
Genetic data are represented by the letters A, C, G, and T. These represent the nucleotides, the building blocks of the genetic material. Genomes can be made up of billions of these information units. To make them easier to compare, they can be displayed next to each other as ‘letter chains’. This traditional sequence-based representation is widespread today. ‘But with hundreds of comparison genomes, it takes a great deal of time to analyse step by step how the genome under investigation differs from each of the comparison genomes,’ said Schönhuth.
‘The new technology enables a simultaneous, integrated analysis of many strains of the same organism. These can be viruses, bacteria, and sometimes even higher organisms,’ explains Jens Stoye. ‘This makes it possible to highlight the similarities and differences between the individual members. In the case of pathogens, it is often even possible to understand and predict the processes that led to the development of particularly infectious strains. ‘The technology can also be used to detect hereditary diseases in humans or to determine which mutations in a tumour have led to strong, abnormal growth.
‘Over the next few years, we want to develop new algorithms and data structures with our project partners that will make computer-assisted pangenomics faster and more user-friendly,’ says Schönhuth. One goal is to develop algorithms for variation graphs. With these programs, the computers search for similarities and differences between the comparative genomes and present the results graphically: ‘Variation graphs enable a rapid and high-resolution differentiation of pathogenic and harmless variants of a virus,’ says Schönhuth. ‘In particular, they also allow us to identify completely novel mutations, such as those that have presumably occurred in the variant of the coronavirus currently breaking out in China and that have led to resistance to the usual medications.‘
The full name of the Pangaia project is ‘Pan-genome Graph Algorithms and Data Integration’. It will run from January 2020 to December 2023. The European Union is funding Pangaia through its Horizon 2020 research framework programme and the University of Milan (Italy) is coordinating the project. Other partners besides Bielefeld University are: the Netherlands Organization for Scientific Research (NWO), Comenius University Bratislava (Slovakia), the biotech companies Geneton (Slovakia) and Illumina Cambridge (Great Britain), the Institut Pasteur (France), Simon Fraser University (Canada), University of Tokyo (Japan), Cornell University, and Pennsylvania State University (both USA).